机器学习之聚类算法(1)
1. 聚类的概念(Clustering)
1.1 聚类的概念
机器学习按照学习形式可以分为“监督学习”与“无监督学习”,在无监督学习中,训练样本的标记信息未知,即没有“标签”,需要通过对无标记训练样本的学习来揭示数据的内在性质与规律,无监督学习任务中研究最多、应用最广的是聚类。
聚类将数据集中相似的样本归到同一个簇中,将不相似的地样本归到不同的簇中,每个簇可能对应于一些潜在的概念(类别),但这些概念对聚类算法而言事先是未知的。这其中的一系列概念可以表示为:
假定样本集$D=\left\{x_1,x_2,\cdots,x_m \right\}$包含$m$个无标记样本,每个样本$x_i=\left\{x_{i1};x_{i2};\cdots;x_{in} \right\}$是一个$n$维特征向量,则聚类算法将样本集$D$划分为$k$个不相交的簇$\left\{C_l | l=1,2,\cdots,k \right\}$,其中,$C_{l’}\cap_{l’\neq l}C_l=\varnothing $且$D=\cup_{l=1}^kC_l$,相应地,我们用$\lambda_j\in\left\{1,2,\cdots,k\right\}$表示样本$x_j$的簇标记,即$x_j\in C_{\lambda_j}$于是,聚类的结果可用包含$m$个元素的簇标记向量$\lambda=\left(\lambda_1;\lambda_2; \cdots;\lambda_m\right)$表示。
1.2 聚类中的性能度量
聚类分析试图将相似对象划为同一簇,不相似的对象归到不同簇,而“相似”主要依靠性能度量。
聚类的性能度量(有效性指标)是用于评估聚类效果的好坏的或作为聚类过程的优化目标的。聚类性能度量大致可以分为两类,一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
1.2.1 外部指标
对数据集$D=\left\{x_1,x_2,\cdots,x_m \right\}$,假定通过聚类给出的簇划分为$C=\left\{C_1,C_2,\cdots,C_k \right\}$参考模型给出的簇划分为$C^=\left\{C_1^,C_2^,\cdots,C_s ^\right\}$。相应地,令$\lambda$与$\lambda^$分别表示$C$与$C^$对应的簇标记向量,将样本两两配对考虑,则可定义:
其中集合$SS$为在$C$中隶属于相同簇且在$C^*$中也隶属于相同簇的样本对,其余同理可以推得,此外$a+b+c+d=\frac{m(m-1)}{2}$
通过以上定义得到聚类性能度量的外部指标:
- Jaccard系数 $JC=\frac{a}{a+b+c}$
- FM指数 $FMI=\sqrt{\frac{a}{a+b}\frac{a}{a+c}}$
- Rand指数 $RI=\frac{2(a+d)}{m(m-1)}$
1.2.2 内部指标
根据簇划分$C=\left\{C_1,C_2,\cdots,C_k \right\}$,定义:
$dist$为样本距离计算公式,$\mu$代表簇$C$的中心点,$avf(C)$对应簇$C$内样本间的平均距离,$diam(C)$对应簇内$C$内样本间的最远距离,$d_\min (C_i,C_j)$为两个簇最近样本间的距离$d_{cen}(C_i,C_j)$为两簇中心点间的距离。
通过以上可以导出以下内部指标:
- DBI指数 $DBI =\frac{1}{k}\sum_{i=1}^k\max_{j\neq i}\left( \frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i,\mu_j)}\right)$
- Dunn指数 $DI=\min_{1\leq i \leq k}\left\{\min_{j\neq i}\left(\frac{d_\min(C_i,C_j)}{\max_{1\leq l \leq k}diam(C_l)}\right)\right\}$
DBI的值越小越好,DI的值越大越好。
1.3 聚类中的距离
性能度量中的内部指标涉及到“距离”的度量,数据的属性可以分为“有序属性”(如{1,2,3}可以直接衡量出各个量之间的距离)与“无序属性”(如{飞机,火车,轮船}不能直接刻画各个量之间的距离)。
其中“有序属性”可以通过闵可夫斯基距离计算:
p=1时,为曼哈顿距离;p=2时为欧式距离;此外当样本空间中不同属性的重要性不同时,可以使用“加权距离”进行计算。
“无序属性”可以通过VDM(value Difference Metric)计算:
其中$m_{u,a}$表示在属性$u$上取值为$a$的样本数,$m_{u,a,i}$表示在第$i$个样本簇中在属性$u$上取值为$a$的样本数,$k$为样本簇数。
对于同时存在“有序属性”与“无序属性”的情况,可以采用混合距离定义,其中有$n_c$个有序属性,$n-n_c$个无序属性:
距离度量需要满足如非负性、同一性、对称性、直递性(两边之和大于第三边)等性质,但相似度度量的过程中使用的距离未必一定要满足距离度量的所有基本性质。
1.4 聚类的分类
看过几个版本的聚类的分类方法,基本是一致的,但也有一点点差异,此处选取周志华《机器学习》一书中的分类方法。
- 原型聚类:假设聚类结构能通过一组原型刻画,算法一般先对原型进行初始化,然后对原型进行迭代更新求解。代表方法包括k-means;LVQ;GMM等。
- 密度聚类:基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现“球形”聚簇的缺点。其核心思想在于只要一个区域中点的密度大于某个阈值,就把它加到与之相近的聚类中去。 通常情况,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的结果。代表方法包括DBSCAN、OPTICS,DENCLUE,WaveCluster等。
- 层次聚类:试图在不同层次对数据集进行划分,从而形成树型的聚类结构,存在“自底而上”的聚合策略,与“自顶而下”的分拆策略。在“自底向上”方案中,初始时每个数据点组成一个单独的组,在接下来的迭代中,按一定的距离度量将相互邻近的组合并成一个组,直至所有的记录组成一个分组或者满足某个条件为止。 代表方法包括:AGNES、BIRCH,CURE,CHAMELEON等。
2.原型聚类——K-均值聚类算法(K-means)
2.1 过程及算法
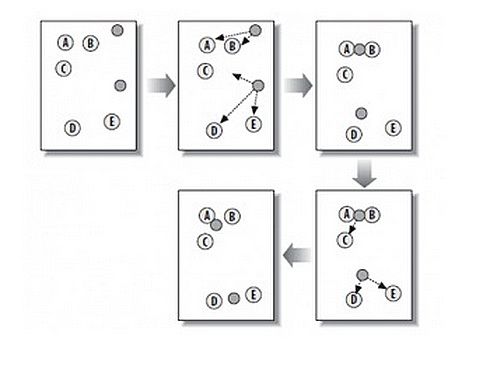
如上图所示,是K均值聚类的原理。对数据集$D=\left\{x_1,x_2,\cdots,x_m \right\}$,K-均值算法针对聚类所得簇划分$C=\left\{C_1,C_2,\cdots,C_k \right\}$最小化平方误差:
其中k是用户给定的簇的个数,$\mu_i$是簇$C_i$的均值向量,即簇的“质心”。找到E的最小值是一个NP困难问题,k-均值算法采用贪心策略,通过迭代优化近似求解,算法首先对于质心(均值向量)进行初始化,随机确定k个初始点作为质心,然后将数据集中的每个点寻找距离其最近的质心,并将该点分给该质心代表的簇,之后更新簇的质心(均值向量)为该簇现有所有点的平均值。
伪代码过程为:
1 | 创建k个点作为起始质心(可以在样本中随机选择k个) |

使用Python建立k-means过程:
1 | from numpy import * |
1 | def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):#kmeans建立,输入数据集、簇个数 |
2.2 优缺点及适用性分析
优点:便于实现
缺点:可能收敛到局部最小值,在大规模数据上收敛较慢
3. 二分K-均值算法(bisecting K-means)
由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选到一个类上,一定程度上克服了算法陷入局部最优状态。 二分KMeans(Bisecting KMeans)算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大限度降低聚类代价函数(也就是误差平方和SSE)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。以上隐含的一个原则就是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好。所以我们就需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果越不好,越有可能是多个簇被当成了一个簇,所以我们首先需要对这个簇进行划分。
1 | def biKmeans(dataSet, k, distMeas=distEclud): |
4.K-均值算法实战:对地图上的点进行聚类
这次没有选择《机器学习实战》课本上的案例,而是选取了2016.12.22周四00:00-00:30之间上海市出租车订单数据中所有正常数据的订单起始点进行聚类(总共137个数据点,数据来源是上学期交通地理信息系统课程)。此外还使用了上海市的路网shp文件,借助geopandas、numpy、matplotlib、pandas等模块,完成这些起始点的聚类,通过此过程我们可以看到热点地区的分布情况。
通过调用clusterOrders(numClust)即可进行进行以上聚类过程,此部分源代码如下,此外还需导入randCent(),kMeans(),biKmeans()函数。
1 | def distSLC(vecA, vecB):#由经纬度转化为距离 |
尝试簇的数目由2至9,得到的聚类结果如下图所示:
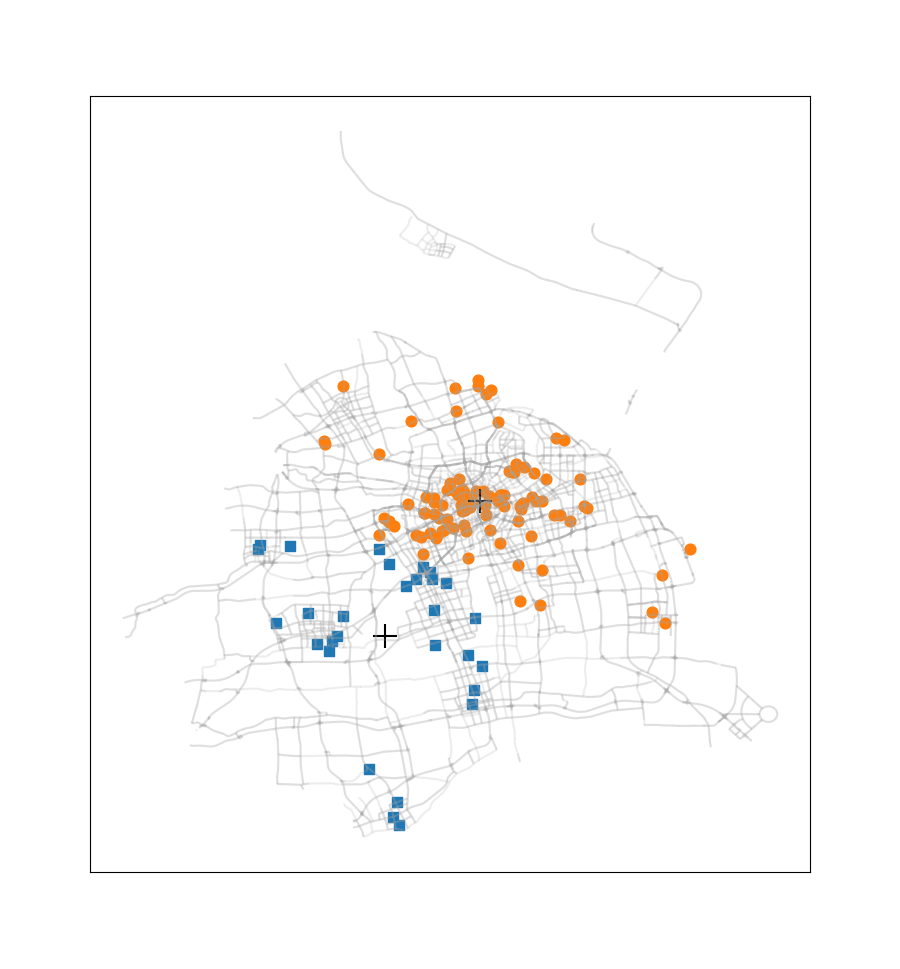
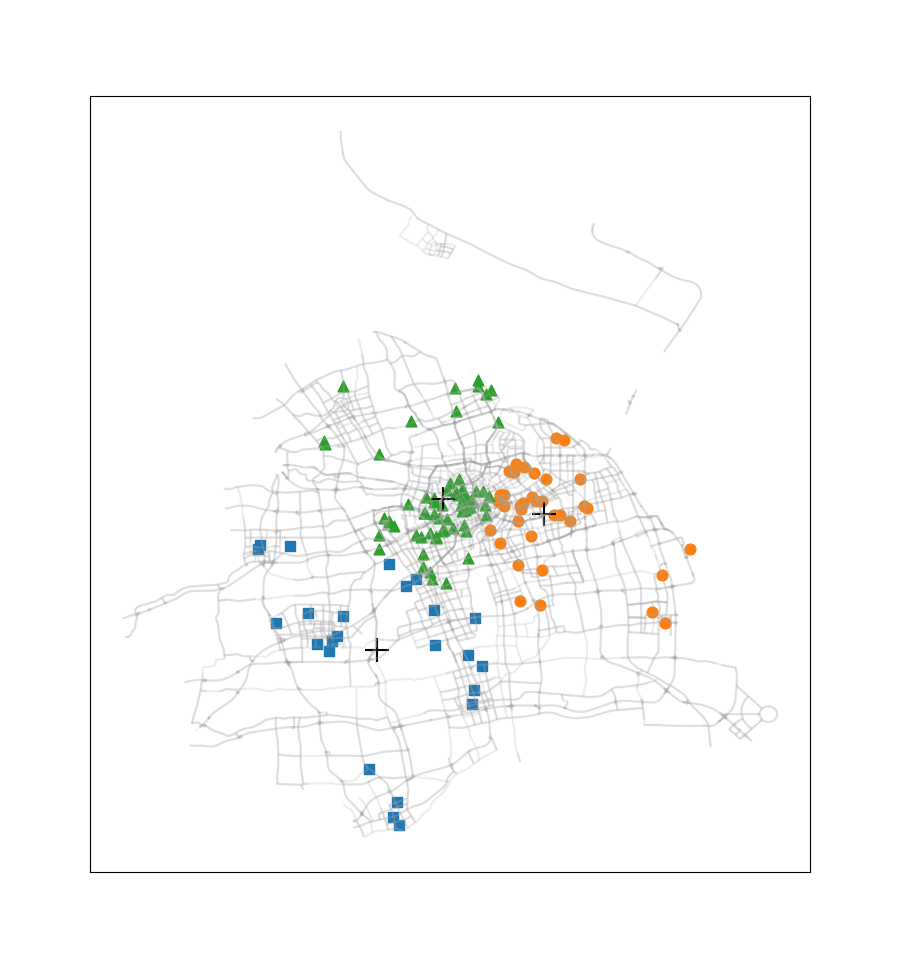
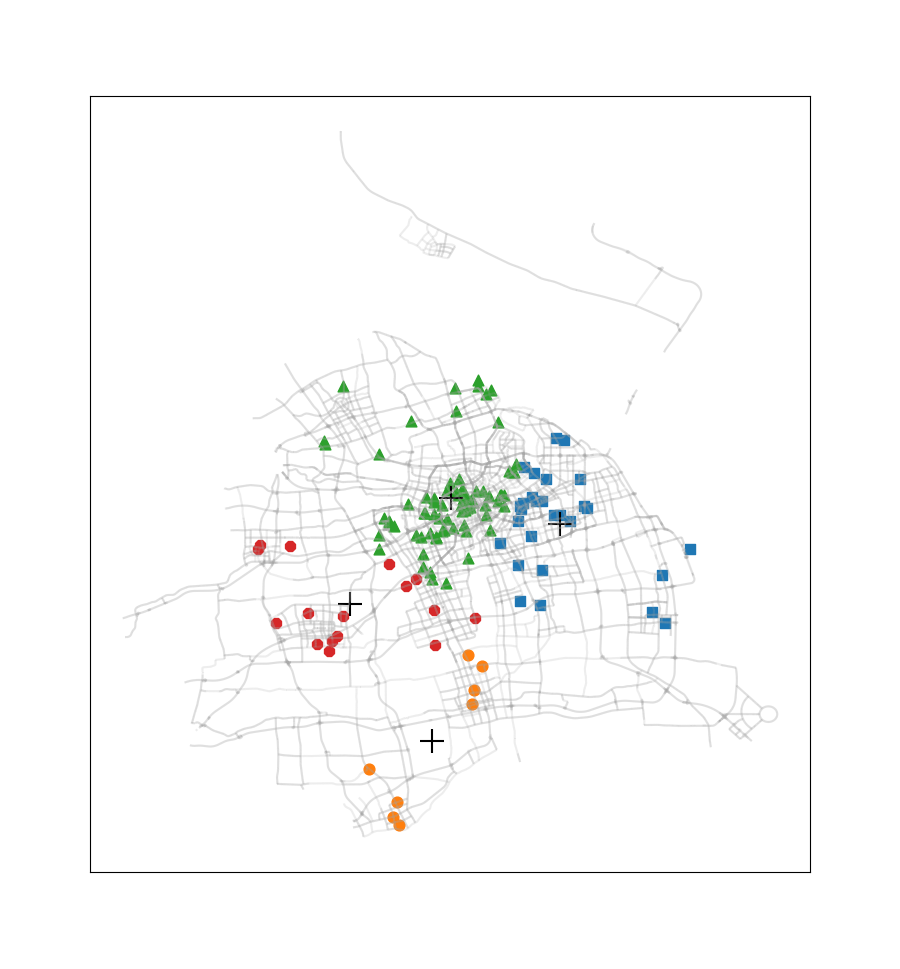
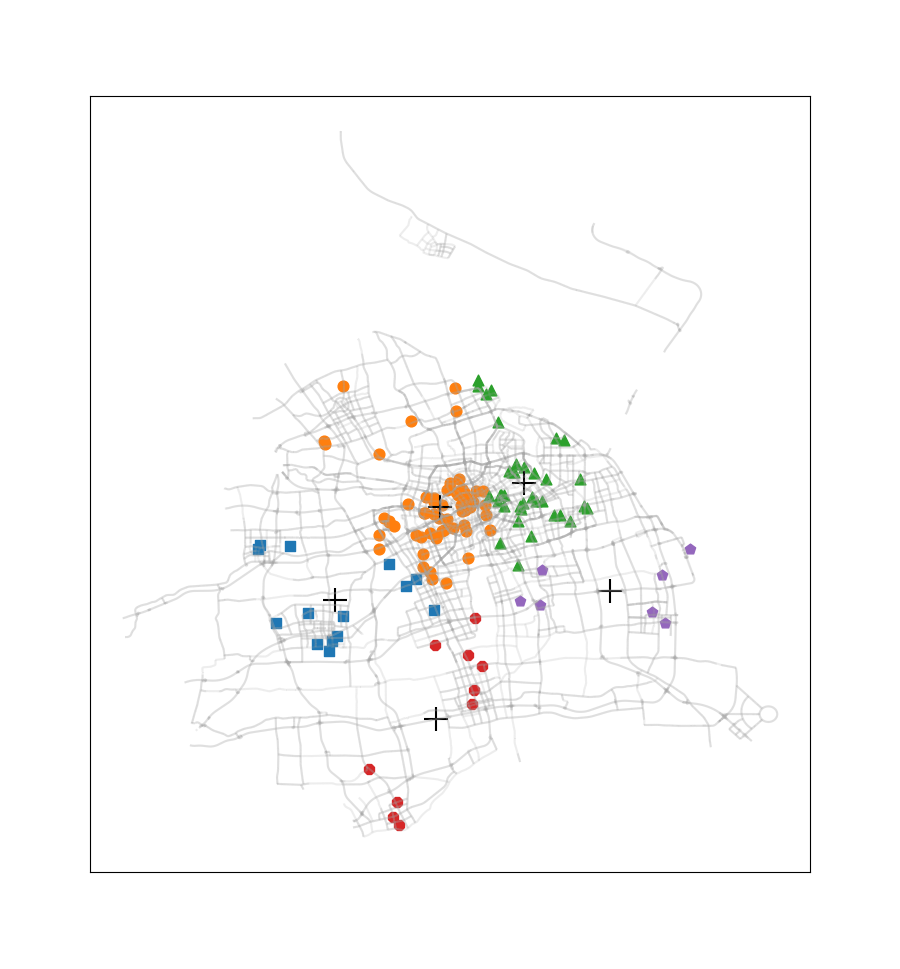
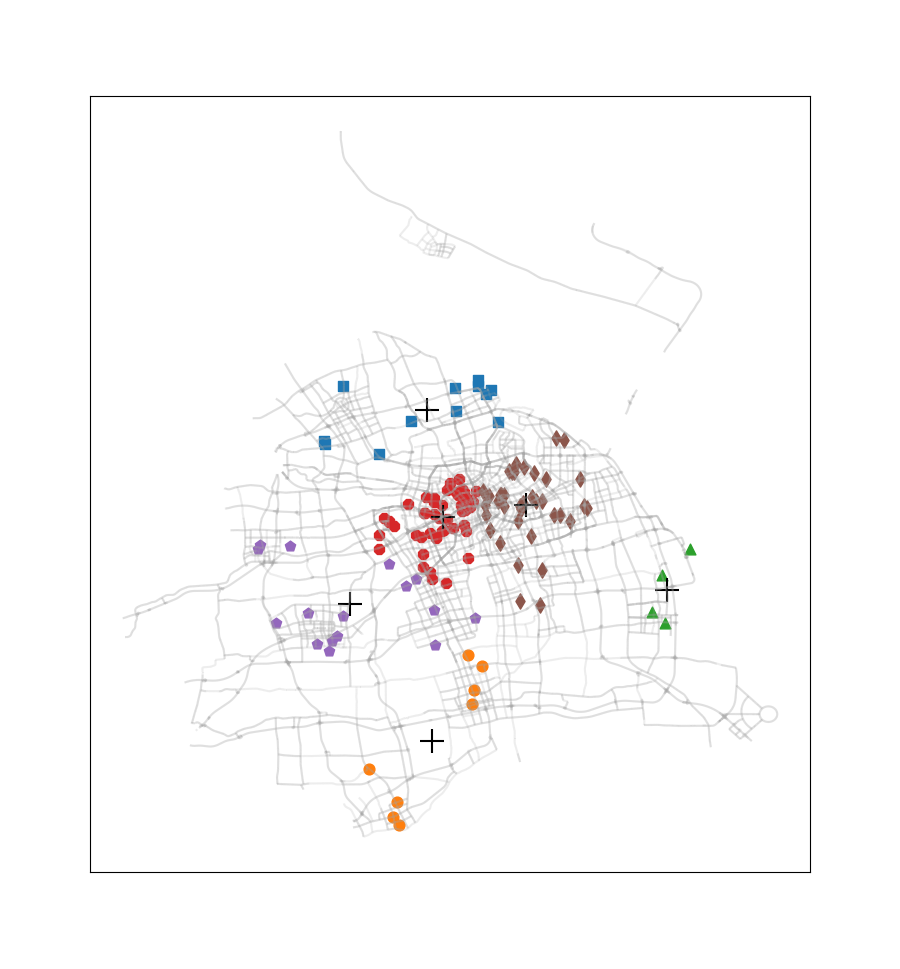
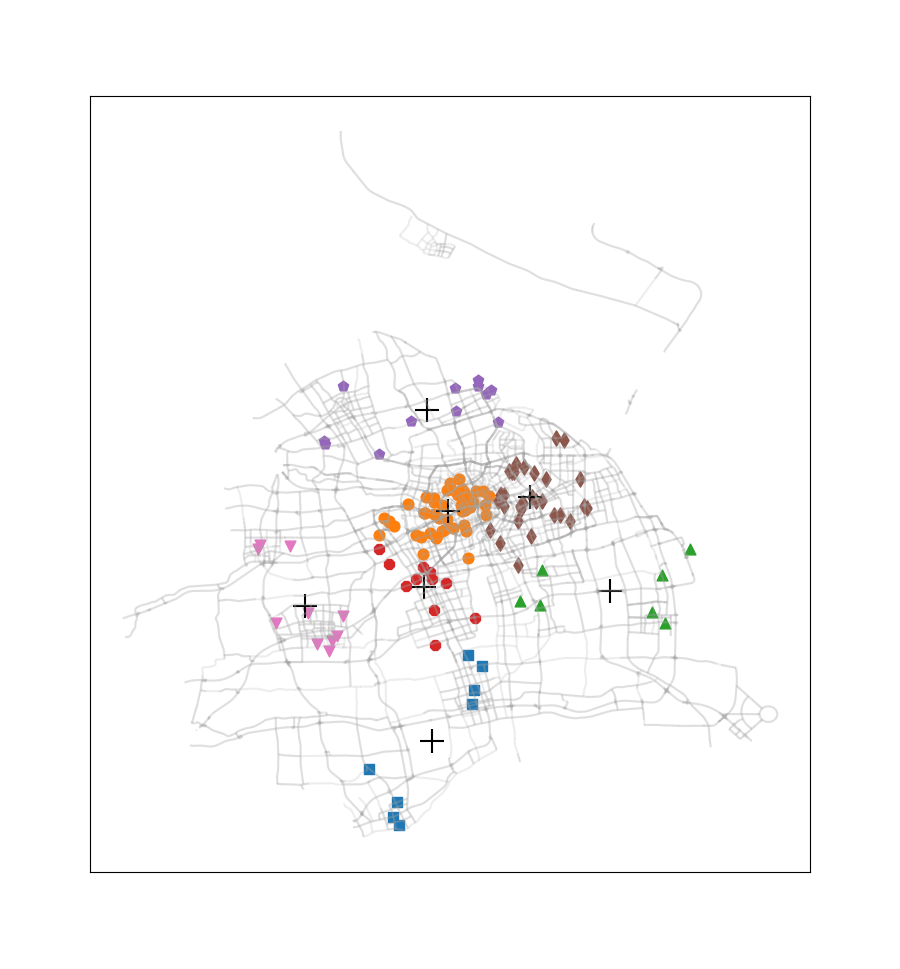
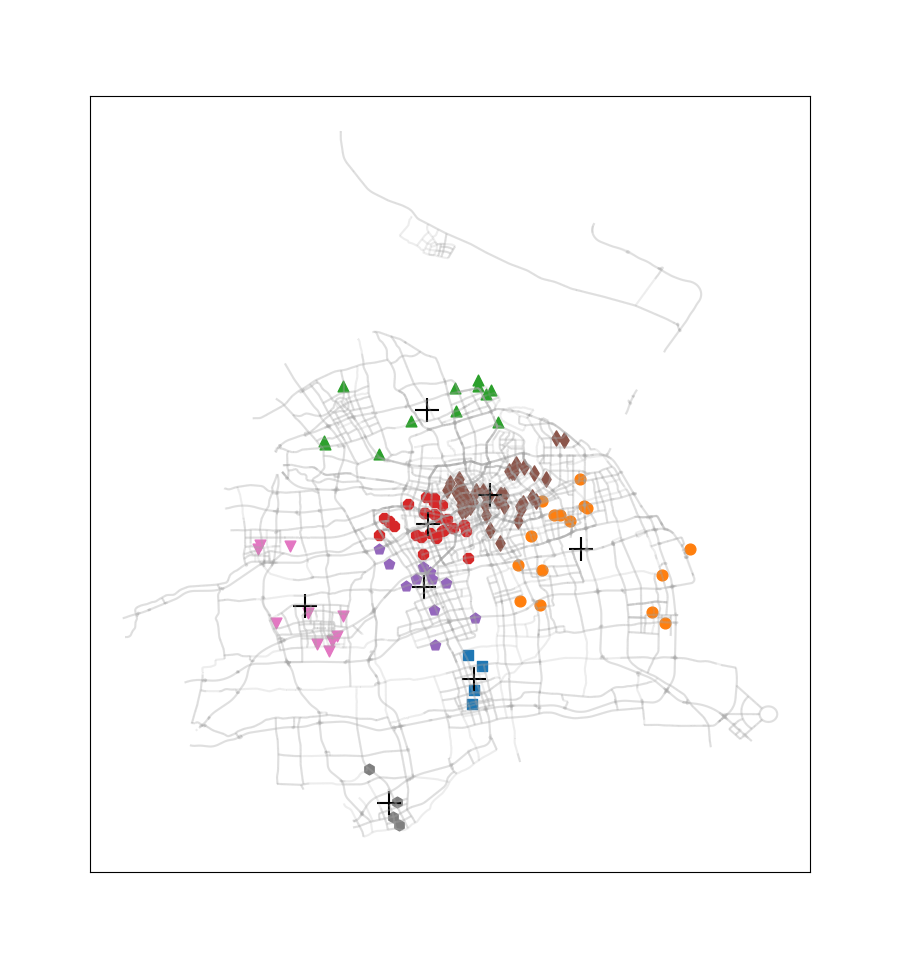
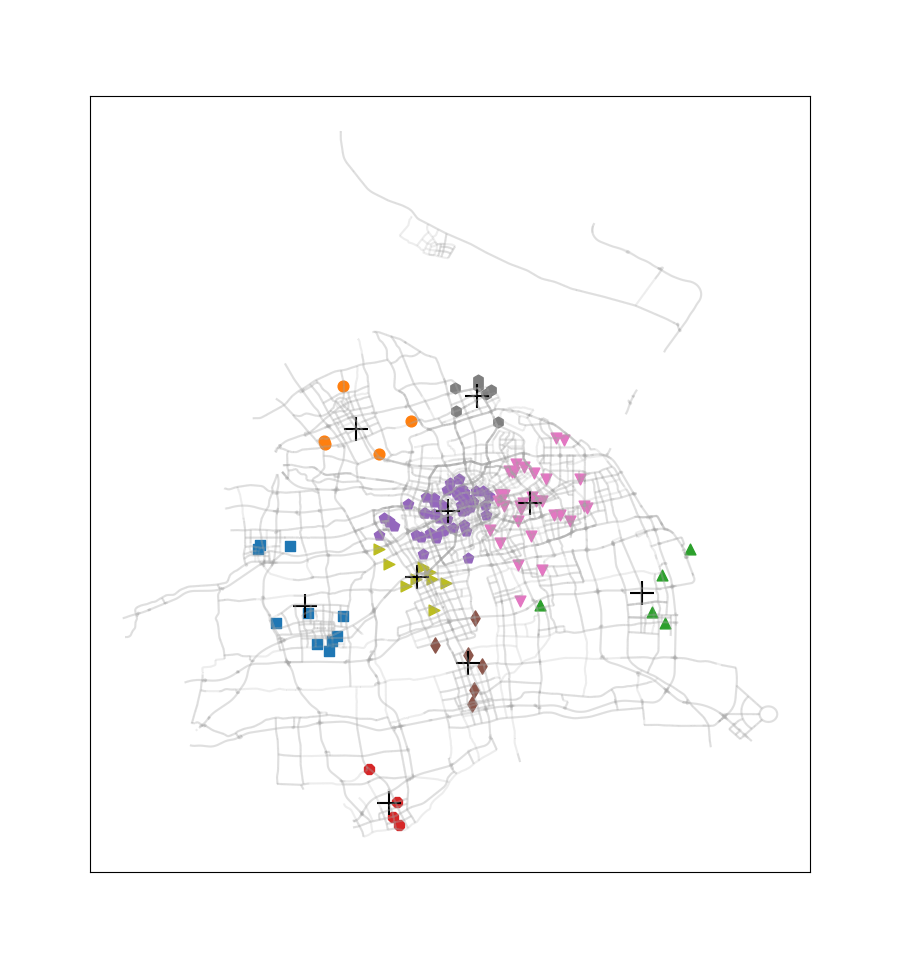
此案例只应用了非常少量的一部分订单数据,在应用于量较大的订单数据时,我们可以不绘制各个订单起始点,而是将每一簇的数目与簇质心‘+’符号的尺寸产生关联,使热点区域的显示更为直观。
关于原型聚类中的GMM高斯混合模型聚类、密度聚类与层次聚类由于内容较多,推导较为复杂,本篇内就不再详细叙述,GMM大概会与EM算法一起写一篇吧!
参考资料
周志华《机器学习》第9章
《机器学习实战》第10章
很多很多没有记录下来的博客